#SQL Server delayed start
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Optimizing SQL Server with the Delayed Start
In today’s fast-paced IT environment, optimizing SQL Server performance and startup times is crucial for maintaining system efficiency and ensuring that resources are available when needed. One valuable, yet often overlooked, feature is the SQL Server services delayed start option. This configuration can significantly enhance your server’s operational flexibility, particularly in environments…
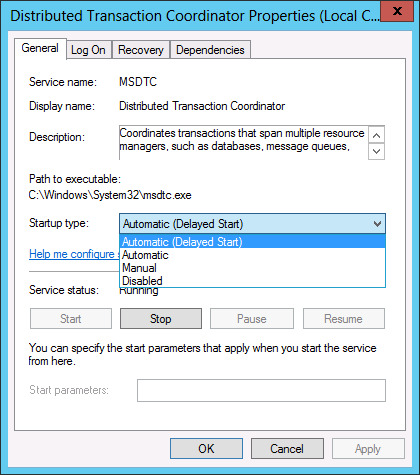
View On WordPress
#SQL Server configuration#SQL Server delayed start#SQL services optimization#SQL startup options#T-SQL examples
0 notes
Text
Microsoft License: Revolutionizing Access to Genuine Microsoft Software for Global Businesses

Barcelona, April 22, 2025 — In an era where digital transformation is no longer optional but essential, the integrity and reliability of software solutions have never been more critical. Microsoft License, a trusted subsidiary of Talee Limited and an official Microsoft Partner, has emerged as a leading provider of 100% genuine Microsoft software licenses, serving businesses, institutions, and IT professionals around the globe. Founded on the principles of transparency, authenticity, and customer empowerment, Microsoft License provides direct access to the full suite of Microsoft products — including Windows operating systems, Microsoft Office, Windows Server, SQL Server, and Microsoft Azure. Each product sold through https://microsoftlicense.com is backed by verifiable license keys and lifetime support, ensuring complete compliance and peace of mind for clients. “With over 12 years in the industry, our goal has always been to simplify software procurement while maintaining the highest standards of legitimacy,” said a Microsoft License spokesperson. “We want to ensure that businesses, regardless of their size or location, can operate with the tools they need — legally, securely, and efficiently.” **Unmatched Value and Immediate Delivery** Unlike traditional resellers, Microsoft License distinguishes itself by offering instant digital delivery of license keys upon purchase. This allows clients to start using their software within minutes of ordering, eliminating unnecessary delays and ensuring productivity is never compromised. Moreover, the company’s unique pricing model enables clients to save up to 70% compared to retail pricing without sacrificing authenticity or quality. Their portfolio caters to individual users, small businesses, educational institutions, and large enterprises alike — all of whom benefit from Microsoft License’s strong vendor relationships and bulk purchasing power. **Lifetime Support and Customer-Centric Approach** What truly sets Microsoft License apart is its commitment to post-purchase service. Customers receive lifetime technical support from a dedicated team of certified professionals, available to assist with installation, activation, and ongoing maintenance. This white-glove support has earned Microsoft License a loyal customer base and exceptional trust scores across international review platforms. With thousands of satisfied clients across Europe, North America, Asia, and the Middle East, the company has positioned itself as a beacon of excellence in the software licensing industry. **A Global Vision for a Secure Digital Future** As part of its long-term vision, Microsoft License continues to invest in cybersecurity education, compliance training, and digital access programs aimed at bridging the digital divide in underserved regions. These initiatives reflect the company's belief in technology as a force for global empowerment. “We see ourselves not just as a reseller but as a partner in our clients' digital journeys,” the spokesperson added. “Whether you're building an enterprise IT infrastructure or simply upgrading your home PC, Microsoft License is here to provide the tools and confidence to move forward.” **Visit and Explore** To learn more about the full range of products and services offered, or to purchase genuine Microsoft software licenses with instant delivery, visit: https://microsoftlicense.com/ Stay connected and follow the latest updates via our website: https://microsoftlicense.com/ About Microsoft License: Microsoft License is an authorized Microsoft Partner and subsidiary of Talee Limited, registered in the United Kingdom. The company specializes in the distribution of authentic Microsoft software licenses with a strong focus on customer service, compliance, and value delivery.
0 notes
Text
Why Is My eCommerce Site Slow Even with Good Hosting?
Introduction
You’re paying for high-performance hosting, but your eCommerce site still loads slowly. Pages lag, product images crawl in, and your bounce rate is skyrocketing. Sound familiar?
Good hosting is only part of the performance puzzle. In this blog, we’ll explore why your eCommerce website development efforts might still result in a slow site — and exactly what you can do to fix it.
Common Reasons Your eCommerce Site Is Still Slow 1. Unoptimized Images Large image files are one of the top culprits of slow load times. Avoid uploading raw photos from DSLR or phone cameras. Use tools like TinyPNG or WebP formats to compress images without losing quality.
Tip: Use lazy loading for product images and carousels.
2. Too Many Third-Party Scripts Live chats, trackers, heatmaps, and plugins often add JavaScript bloat. Scripts from Facebook Pixel, Google Tag Manager, and review widgets can block rendering.
Tip: Load non-critical scripts asynchronously or defer them.
3. Heavy Themes or Builders Are you using a feature-heavy theme or drag-and-drop builder? Themes built for flexibility can be bloated. Shopify and WooCommerce themes with unnecessary animations or sliders slow everything down.
Tip: Use lightweight, performance-optimized themes (like Dawn for Shopify or Astra for WooCommerce).
4. Inefficient Code or Customizations Custom code by freelancers or agencies might not be optimized. Loops, queries, or AJAX calls in product pages could slow down your site.
Tip: Audit your codebase regularly or use tools like GTmetrix and PageSpeed Insights to find bottlenecks.
5. Uncached Dynamic Content Even with good hosting, uncached pages can cause lags. Product pages, category filters, and carts are often dynamically generated.
Tip: Use page caching (e.g., Varnish, WP Rocket) and CDN edge caching (Cloudflare, BunnyCDN).
6. Large or Unoptimized Database Your store database grows with every product, order, and customer. Poor indexing or bloated tables cause slow queries. This is especially common in WooCommerce or Magento.
Tip: Optimize your database monthly using plugins like WP-Optimize or direct SQL commands.
7. Overloaded Frontend with Too Many Requests Each button, font, icon, and script is an HTTP request. Too many requests slow everything down.
Tip: Minify CSS and JS files, combine where possible, and reduce HTTP requests using tools like Autoptimize.
8. No Content Delivery Network (CDN) Even with fast hosting, visitors farther from your server face delays in loading your website.
Tip: Use a CDN like Cloudflare or BunnyCDN to serve assets closer to your users worldwide.
How to Diagnose the Real Problem Use these free tools to pinpoint the exact cause:
Google PageSpeed Insights — shows Core Web Vitals
GTmetrix — waterfall view of every request
Chrome DevTools — identify blocking assets
Pingdom — great for global speed tests
Hosting Alone Isn’t Enough Your hosting might be fast, but your site architecture, plugins, and content delivery strategy matter just as much.
Think of hosting as a highway. If your store is a traffic jam of scripts, bloated images, and detours, speed still suffers. That’s why many businesses turn to a best eCommerce website development company that can take performance optimization seriously from the ground up.
Conclusion If you’re wondering, “Why is my eCommerce site slow even with good hosting?”, the answer likely lies in:
Poor frontend performance
Unoptimized assets
Database or plugin bloat
Start with a full site audit. Optimize images, scripts, and theme. Use caching and a CDN.
Speed isn’t just about user experience — it’s an SEO and sales factor. A few strategic improvements can significantly reduce load times, improve conversions, and lower bounce rates. For scalable and reliable results, consider working with an experienced eCommerce solutions provider in India that understands performance, user behavior, and growth strategies.
0 notes
Text
Your Dashboard is Slower Than It Should Be – Here’s How to Fix It!
We've all been there. You log into your dashboard, expecting instant insights, but instead, you're greeted with a painfully slow loading screen. Your frustration grows, and by the time your data finally loads, you’ve lost valuable minutes—or worse, your patience.

A slow dashboard isn’t just an inconvenience; it’s a business killer. It frustrates users, delays critical decision-making, and can even impact revenue. But don’t worry! Whether you're a dashboard developer, business owner, or product manager, I’ve got you covered. Let’s break down why your dashboard is slow and, more importantly, how to fix it.
1. Understanding Why Your Dashboard is Slow
Before we dive into solutions, let's diagnose the common performance bottlenecks:
Heavy Queries & Database Overload
If your dashboard relies on a database to fetch real-time information, poorly optimized queries can cause significant slowdowns. Think about it like a crowded coffee shop: if every customer orders a highly customized drink (complex query), the barista (database) gets overwhelmed.
Inefficient Data Fetching
Fetching too much data at once or making too many API calls leads to sluggish performance. Imagine trying to carry 15 grocery bags in one trip—it’s just not efficient.
Front-End Rendering Issues
Even if your backend is lightning-fast, a poorly optimized front-end can slow everything down. Unnecessary re-renders, unoptimized JavaScript, or rendering massive amounts of data all contribute to sluggish performance.
Lack of Caching
If your dashboard fetches the same data repeatedly without caching, it’s like checking your fridge every five minutes to see if food magically appeared. Instead, cache frequently used data to improve speed.
Poor Data Structure
If your data isn’t indexed properly, finding what you need can be like searching for a needle in a haystack.
2. Diagnosing Dashboard Performance Issues
Before we start fixing things, let's find the root cause. Here are some tools and techniques to help:
Google Lighthouse & PageSpeed Insights
Use these tools to check your front-end performance. They pinpoint render-blocking scripts, slow-loading assets, and other issues.
Database Query Profilers
If your dashboard pulls data from a database, tools like MySQL EXPLAIN or PostgreSQL EXPLAIN ANALYZE can help identify slow queries.
Chrome DevTools & Network Analysis
Monitor API response times, find unnecessary requests, and optimize network traffic.
Server Logs & Load Testing
Check backend performance by analyzing server logs and running load tests to see how well your system handles heavy traffic.
3. Optimizing Backend Performance
Efficient Query Design & Data Management
Use Indexed Databases: Indexing speeds up searches significantly. Think of it as a well-organized library versus one with books scattered everywhere.
Optimize SQL Queries: Avoid using SELECT * when you only need specific fields.
Implement Pagination: Load data in chunks rather than all at once to improve responsiveness.
Normalize vs. Denormalize Data: Balance between reducing redundancy (normalization) and speeding up queries (denormalization).
Caching Strategies for Speed Boost
Redis or Memcached: Store frequently accessed data to reduce database queries.
Edge & Browser Caching: Cache static content so it doesn’t reload unnecessarily.
Pre-aggregated Data Storage: If your dashboard requires heavy calculations, consider storing pre-computed results.
4. Optimizing API Calls & Data Fetching
Reduce the Number of API Calls
Instead of making multiple small API requests, batch them to reduce network load.
Use WebSockets for Real-Time Data
Polling APIs every few seconds? Switch to WebSockets for faster real-time updates with less load on the server.
Optimize API Response Payloads
Only send the data you need. A bloated API response slows down everything.
Leverage GraphQL
Unlike REST APIs that return fixed responses, GraphQL lets you request only the fields you need, improving efficiency.
5. Front-End Optimization for Faster Dashboards
Minify & Bundle JavaScript and CSS
Large scripts can slow down dashboard loading times. Minify and bundle them to improve performance.
Lazy Loading & Async Loading
Only load content when needed. For example, don’t load a chart until the user scrolls to it.
Optimize Component Rendering
If you’re using React, Vue, or Angular, avoid unnecessary re-renders by using memorization and state management best practices.
Use Virtualization for Large Data Tables
Rendering thousands of rows at once is a bad idea. Instead, use virtualization techniques like React Virtualized to load only what the user sees.
Choose the Right Visualization Library
Not all charting libraries are created equal. Use lightweight options like Chart.js instead of more complex libraries if you don’t need advanced features.
6. Preventing Future Slowdowns
Regular Performance Audits & Load Testing
Schedule periodic performance reviews to catch slowdowns before users complain.
Monitor API Latency & Server Response Times
Use tools like New Relic, DataDog, or Prometheus to keep an eye on your backend.
Set Up Automated Alerts for Performance Drops
Be proactive—set up alerts for when response times exceed a certain threshold.
Keep Your Tech Stack Updated
Old versions of frameworks and libraries can be less efficient. Regularly update your stack for performance improvements.
Conclusion
Slow dashboards are frustrating, but the good news is they’re fixable. By diagnosing performance bottlenecks, optimizing your backend and front-end, and implementing long-term monitoring, you can create a dashboard development services that loads in seconds, not minutes.
Take action today—start with a performance audit and apply at least one of these improvements. Your users (and your business) will thank you!
0 notes
Text
Shift-Left Testing for APIs: How Early Automation Improves Quality

Traditional software testing often takes place at the later stages of development, leading to late defect detection, high remediation costs, and delayed releases.
Shift-Left Testing moves testing activities earlier in the development cycle, allowing teams to catch issues sooner and improve overall software quality. When applied to API testing, this proactive approach enhances performance, security, and reliability while reducing technical debt.
What is Shift-Left API Testing? A Smarter Approach to Automation
Shift-Left API testing is the practice of integrating API testing into the early stages of development, rather than waiting until the final phases. This approach involves:
Automating API Tests Early – Creating automated test suites as soon as API endpoints are designed.
Integrating with CI/CD Pipelines – Running tests continuously to detect issues before deployment.
Mocking and Service Virtualization – Simulating API behaviors to test dependencies in isolation.
Early Performance and Security Testing – Identifying bottlenecks and vulnerabilities from the start.
How Early API Automation Improves Quality
Automation is the cornerstone of effective Shift-Left Testing. By automating API tests, teams can achieve faster feedback loops, consistent test execution, and improved test coverage. Here’s how early automation improves API quality:
1. Validate API Contracts Early
API contracts, such as OpenAPI or Swagger specifications, define how an API should behave. Automated tools like Postman, SwaggerHub, or Pact can validate these contracts during the design phase. This ensures that the API adheres to its specifications before any code is written.
2. Automate Functional Testing
Functional testing ensures that the API works as expected. By automating functional tests using tools like RestAssured, Karate, or SoapUI, teams can quickly verify endpoints, request/response payloads, and error handling. These tests can be integrated into CI/CD pipelines for continuous validation.
3. Performance Testing from the Start
Performance issues in APIs can lead to slow response times and system crashes. Tools like JMeter or Gatling allow teams to automate performance tests early in the development process. This helps identify bottlenecks and scalability issues before they impact users.
4. Security Testing in the SDLC
APIs are a common target for cyberattacks. Automated security testing tools like OWASP ZAP or Burp Suite can scan APIs for vulnerabilities such as SQL injection, broken authentication, or data exposure. Integrating these tools into the SDLC ensures that security is baked into the API from the start.
5. Continuous Feedback with CI/CD Integration
Automated API tests can be integrated into CI/CD pipelines using tools like Jenkins, GitLab CI, or CircleCI. This provides continuous feedback to developers, enabling them to address issues immediately and maintain high-quality standards throughout the development process.
Best Practices for Implementing Shift-Left API Testing
1. Define API Test Cases Early
Design test cases alongside API specifications to ensure coverage of all functional and non-functional requirements.
2. Leverage API Mocking
Use mocking tools (like WireMock or Postman Mock Server) to test API behavior before actual development.
3. Automate Regression Testing
Implement API regression tests to validate new code changes without breaking existing functionality.
4. Implement Security Testing from the Start
Use security testing tools like OWASP ZAP and Burp Suite to identify vulnerabilities in APIs early.
5. Optimize API Performance Testing
Incorporate tools like JMeter or k6 to measure API response times, load handling, and scalability.
Conclusion
Shift-Left Testing is a game-changer for API development. By integrating testing early in the SDLC and leveraging automation, teams can ensure that APIs are reliable, performant, and secure from the start. This not only improves the quality of APIs but also accelerates delivery, reduces costs, and enhances customer satisfaction.
In today’s competitive landscape, quality is not an afterthought—it’s a priority. Embrace Shift-Left Testing for APIs and take the first step toward building robust, high-quality software systems.
Partner with Testrig Technologies for Expert API Testing
As a leading API Automation Testing Company, at Testrig Technologies, we specialize in Shift-Left API Testing and automation, helping businesses enhance API quality and performance. Our team ensures seamless integration, early defect detection, and optimized testing strategies. Contact us today
0 notes
Text
Empowering Data-Driven Decision Making with Microsoft Power BI
Businesses today generate massive amounts of data, yet many struggle to translate it into actionable insights. Microsoft Power BI offers a solution by transforming complex data into intuitive visualizations and real-time analytics that empower organizations to make informed decisions. Charter Global specializes in guiding businesses to harness the full potential of Power BI, enabling smarter strategies, improved operational efficiency, and data-backed decision-making across all levels of an organization.
Exploring the Power of Microsoft Power BI
Microsoft Power BI stands out as a premier business intelligence tool, combining user-friendly interfaces with robust capabilities for data analysis and visualization. Businesses using Power BI gain access to:
Interactive Dashboards: Customizable dashboards provide real-time metrics tailored to specific business needs, offering a clear view of performance at a glance.
Comprehensive Data Integration: Power BI seamlessly integrates with hundreds of data sources, including Excel, SQL Server, Dynamics 365, and cloud platforms like Azure, consolidating data into a unified view.
AI-Driven Insights: Built-in artificial intelligence tools enhance data analysis by identifying trends, forecasting outcomes, and uncovering hidden patterns in data.
Scalability for Any Organization: From small startups to global enterprises, Power BI’s scalable features adapt to a wide range of business requirements.
How Power BI Transforms Businesses
Organizations adopting Power BI experience significant benefits, such as:
Enhanced Operational Efficiency: With automated data processing and intuitive reporting, teams spend less time on manual tasks and more time on strategic initiatives.
Improved Decision-Making: Access to accurate, up-to-date data ensures leaders make decisions based on facts, not assumptions.
Cross-Department Collaboration: Shared dashboards and reports foster alignment across teams, breaking down silos and creating a unified approach to achieving business goals.
Charter Global: Your Partner for Power BI Success
Implementing and optimizing Power BI requires the right expertise to align the tool’s capabilities with your unique business needs. Charter Global delivers tailored Power BI solutions that drive measurable results, including:
Comprehensive Implementation Services: From initial setup to custom configuration, our experts ensure Power BI is seamlessly integrated into your existing systems.
Data Modeling and Analysis: Charter Global creates advanced data models that uncover deeper insights and provide a solid foundation for predictive analytics.
Custom Dashboards and Reports: We design interactive dashboards tailored to your specific business objectives, delivering actionable insights at your fingertips.
Ongoing Support and Training: Our team provides continuous support and training to empower your staff to maximize the platform’s potential.
Success Stories: Power BI in Action

Many organizations have achieved transformative outcomes with Power BI:
A manufacturing firm improved its supply chain efficiency by integrating Power BI with IoT data, reducing delays and optimizing inventory.
A retail business enhanced customer experience by analyzing purchasing behaviors and adjusting inventory in real-time using Power BI dashboards.
A healthcare provider used Power BI’s AI tools to predict patient trends, improving care outcomes while reducing operational costs.
Why Choose Charter Global
Charter Global not only provides technical expertise but also focuses on delivering solutions aligned with your strategic goals. Our partnership approach ensures every Power BI implementation is tailored to meet the unique challenges of your industry.
Start Your Power BI Journey Today
Data-driven decision-making is no longer optional, it’s a requirement to stay competitive. With Microsoft Power BI and Charter Global��as your partner, you can transform your business with smarter insights and strategic actions.
Contact Charter Global today to explore how our Power BI solutions can elevate your business intelligence capabilities. Book a consultation with one of our subject matter experts, email us at [email protected] or call us at +1 770–326–9933.
0 notes
Text
Essential Tips for Hiring a Web Developer

Creating a professional website is a critical step for any business. To achieve this, you need to hire web developers who have the right skills and experience. Here are essential tips to help you hire the perfect web developer.
Define Your Project Requirements
Clearly outline your website’s goals and requirements. Decide on the type of website you need, the features you want, and your budget. This will help you find a developer who fits your needs.
Identify the Right Developer
Different projects require different types of developers:
Front-End Developers: Specialize in the website’s visual aspects.
Back-End Developers: Handle server-side functionality.
Full-Stack Developers: Capable of both front-end and back-end development.
Review Their Portfolio
Check the developer’s portfolio to see their past work. Look for projects similar to yours to ensure they have the necessary experience.
Check Technical Proficiency
Ensure the developer is skilled in the relevant technologies, including:
HTML/CSS for design and layout.
JavaScript for interactivity.
Frameworks and Libraries such as React, Angular, or Node.js.
Database Management with SQL or NoSQL databases.
Assess Problem-Solving Skills
Good developers need to solve problems effectively. Discuss past challenges and how they resolved them to gauge their problem-solving abilities.
Communication Skills
Effective communication is crucial. Make sure the developer understands your vision and can provide regular updates.
Availability and Time Commitment
Ensure the developer can commit enough time to your project. Discuss timelines and set clear milestones to avoid delays.
Client Testimonials
Client testimonials and references provide insights into the developer’s reliability and professionalism. Contact previous clients to learn about their experiences.
Discuss Costs Upfront
Talk about pricing and payment terms early in the process. A detailed contract outlining the project’s cost and payment schedule can prevent misunderstandings.
Start with a Small Project
If you’re unsure, start with a smaller task to test the developer’s skills and compatibility with your team before committing to a larger project.
Conclusion
Hiring the right web developer is essential for creating a successful website. By defining your project requirements, assessing technical skills, and ensuring good communication, you can find a developer who meets your needs. Follow these tips to hire a web developer who will help you achieve your website goals.
0 notes
Text
So, I've eliminated a few paths already. One has nice examples that the author says are scripts. They're not Batch commands. If they're PowerShell, I don't have the right module (and it doesn't look right to my untrained eye). So what are they? Another was supposedly learning to use ScriptDOM, but no explanation of what to create is included. Maybe I'm too inexperienced to understand some stuff, but if you don't include at least a file type I'm fairly sure you skipped something.
So I'm trying this. It's worth a shot. First step, have a database project in VS. Uhm... I've never done that. I know why we should. But my work has a history of not requiring programmers to document what we do on production systems. Finally got the server admins doing it a while ago, but folks like me live dangerously. Grumble.
So - step 1, create a database. It's not a listed step, but apparently you don't do the creation in VS. There's no step for it in the template listing at least.
So instead I'm doing https://medium.com/hitachisolutions-braintrust/create-your-first-visual-studio-database-project-e6c22e45145b
Step one: in SSMS run the command:
CREATE DATABASE TCommon
T for temporary, and Common is a database I've already got going. It's for non-secure tools/programs/etc. that any of the other databases should be able to access.
Now to start up VS 2022. We begin a new project and search for database templates.
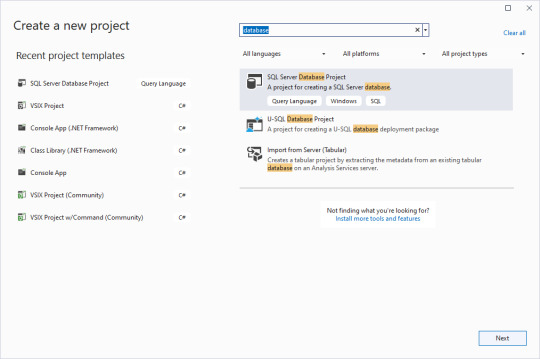
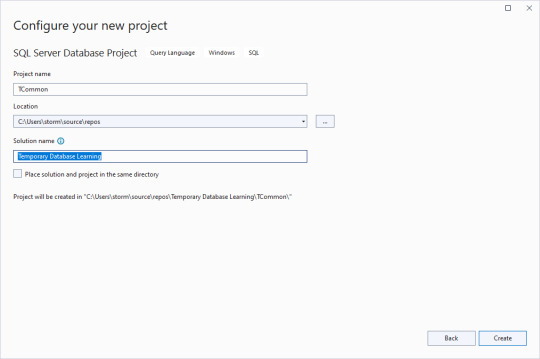
Clear the checkbox for putting the solution and project in the same directory, and give an overarching name to the solution. That way you can have multiple database projects worked on inside of one solution.
Next, we import the blank database so we have a test bed based off what is in production. Right click on the solution name, select Import, then Database.
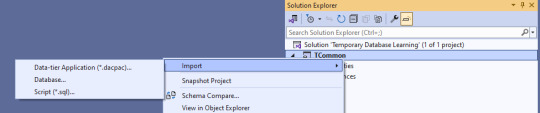
The import database wizard looks like this after the connection is set.
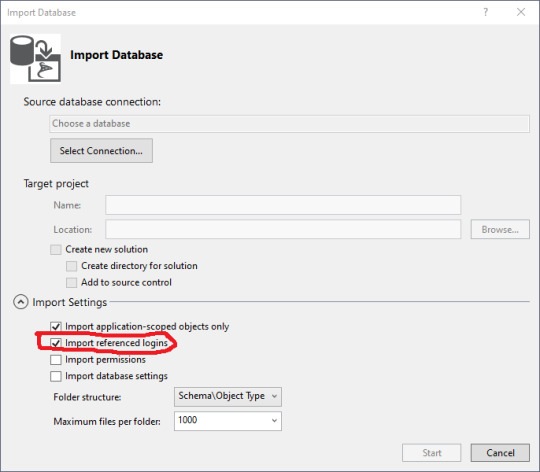
Blackburn suggests that you turn off the importation of referenced logins so you don't accidentally alter permissions. Sound strategy.
Then you can click on the "Select Connection" button.
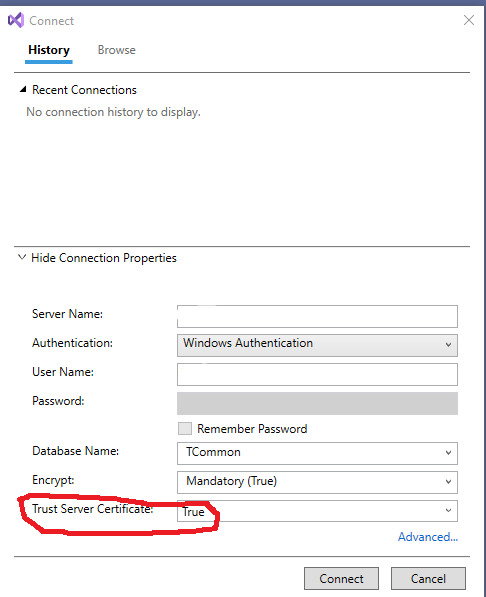
On my workstation, I have to Show Connection Properties, then change the default for Trust Server Certificate to True for it to make a connection. I'm running a test version of SQL Server and didn't set up the certificates.
Click on Connect. Then on the Import Database window, click Start.
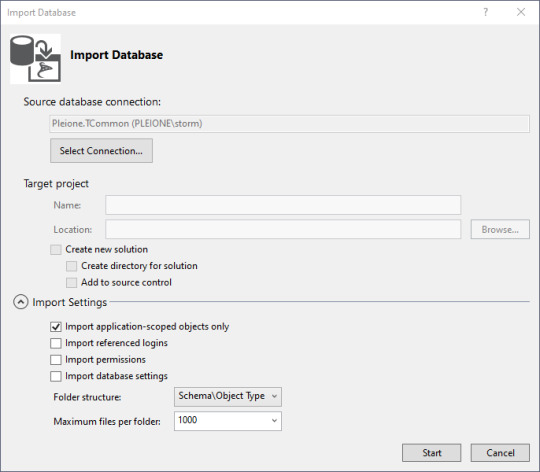
With a blank database, it's fairly anticlimactic, but there really is a connection now to the database, and the properties are copied to your work area. The summary tells you where the log is stored. Then click "Finish" to continue on.
Next, we'll add some objects in. Right click in the Solution Explorer pane, then click Add, then New Item. Lots of little goodies to play with. Since I've been trying to match a project from another site, I need to create a schema to store the objects in. Schemas are part of Security, and there's my little object. I select the schema, give it a name down below, and click Add.
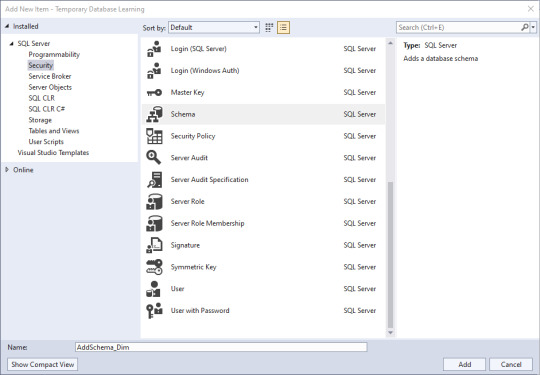
Well, not quite what I expected to happen: CREATE SCHEMA [AddSchema_Dim]
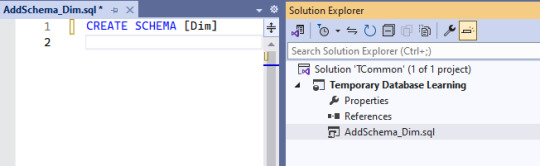
But that's changeable. And in making that change, the solution's object has the name I wanted, and the code has the actual name of the schema I want.
Now, lets add a table.
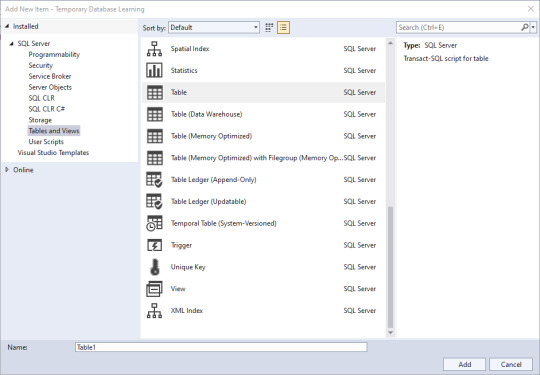
If you're like me, you've used a few of these, but not all of them. Time to do research if you're unsure, but I'm going to go with a simple table for this demonstration. Since I know the name of the solution object will take the name I put in the bottom, I'll name this one AddTable_Dim.Date, and know that I need to edit the actual code.
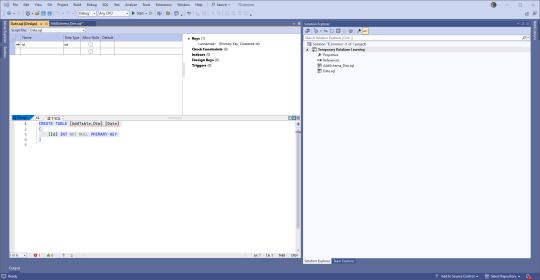
You have choices. If you're used to creating tables using the upper part of the pane where there is a GUI type of set up, go for that. If you're used to typing things out, go to the lower part. Or mix and match! VS will keep the two in sync.
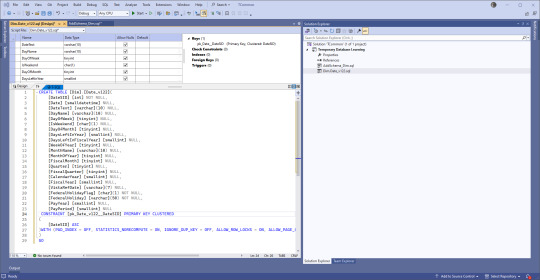
Instead of 'ID' we use 'SID' for Surrogate Identifier. The intake process sets up the unique (across a table) SID values and follows rules that help us track issues backwards to the original location where the data came from.
Second, there's a version number in there. We have the same tables across various enclaves (groups of servers), and we keep the versions the same between all but our development enclave. But instead of forcing our developers and end users to keep up, we use views that are in the databases they work from to expose the data. Many times we don't need to change the views at all which is easier on people that don't need to memorize a few hundred tables and variations.
I'm going to cut this off here, and start working on the next post. Back soon!
0 notes
Text
How To Setup ProxySQL(MySql Proxy) Server ? Part -2

In the previous article - How To Setup ProxySQL Server? PART-1, we learned about setting up ProxySQL and this article is more on the same So moving forward with what we had from PART-1 Our Scenario: Host OS: Ubuntu 18.04 RAM: 2GB memory Proxy server: 172.31.2.24 Master IP: 172.31.2.196 Slave IP:-172.31.2.162 Let's Start 1. Configure Monitoring ProxySQL constantly monitors the servers it has configured. To do so, it is important to configure some interval and timeout variables ( in milliseconds ). we can do it by a simple SQL command. the value of 2000 for variable_value=2000 is for the interval. Admin> UPDATE global_variables SET variable_value=2000 WHERE variable_name IN ('mysql-monitor_connect_interval','mysql-monitor_ping_interval','mysql-monitor_read_only_interval'); Query OK, 3 rows affected (0.00 sec) Admin> UPDATE global_variables SET variable_value = 1000 where variable_name = 'mysql-monitor_connect_timeout'; Query OK, 1 row affected (0.00 sec) Admin> UPDATE global_variables SET variable_value = 500 where variable_name = 'mysql-monitor_ping_timeout'; Query OK, 1 row affected (0.00 sec) Admin> LOAD MYSQL VARIABLES TO RUNTIME; Query OK, 0 rows affected (0.00 sec) Admin> SAVE MYSQL VARIABLES TO DISK; Query OK, 116 rows affected (0.02 sec) With the below configuration, servers will only be shunned in case the replication delay exceeds 60 seconds ( 1 min) behind the master Admin> UPDATE mysql_servers SET max_replication_lag=60; 2. Check Backend Status when our servers are under ProxySQL we can monitor its status with the below command and shows that ProxySQL can successfully connect to all backends. mysql> select * from monitor.mysql_server_ping_log order by time_start_us desc limit 3; +--------------+------+------------------+----------------------+------------+ | hostname | port | time_start_us | ping_success_time_us | ping_error | +--------------+------+------------------+----------------------+------------+ | 172.31.2.162 | 3306 | 1563269179814946 | 549 | NULL | | 172.31.2.196 | 3306 | 1563269179787950 | 494 | NULL | | 172.31.2.162 | 3306 | 1563269177825857 | 541 | NULL | +--------------+------+------------------+----------------------+------------+ 3. Check Query Distribution Here we will use "sysbench" user to check query distributions on the cluster, the output of the command shows the number of queries executed per host of ProxySQL mysql> select hostgroup,srv_host,status,Queries,Bytes_data_sent,Latency_us from stats_mysql_connection_pool where hostgroup in (0,1); +-----------+--------------+--------+---------+-----------------+------------+ | hostgroup | srv_host | status | Queries | Bytes_data_sent | Latency_us | +-----------+--------------+--------+---------+-----------------+------------+ | 0 | 172.31.2.196 | ONLINE | 0 | 0 | 512 | | 1 | 172.31.2.162 | ONLINE | 1 | 18 | 500 | | 1 | 172.31.2.196 | ONLINE | 0 | 0 | 512 | +-----------+--------------+--------+---------+-----------------+------------+ 4. Troubleshoot General ProxySQL issues Let's check for host status with the command and if the third column shows the status is SHUNNED then ProxySQL won't send any queries until it comes back to ONLINE. mysql> select hostgroup,srv_host,status,Queries,Bytes_data_sent,Latency_us from stats_mysql_connection_pool where hostgroup in (0,1); +-----------+--------------+---------+---------+-----------------+------------+ | hostgroup | srv_host | status | Queries | Bytes_data_sent | Latency_us | +-----------+--------------+---------+---------+-----------------+------------+ | 0 | 172.31.2.196 | ONLINE | 0 | 0 | 512 | | 1 | 172.31.2.162 | SHUNNED | 1 | 18 | 500 | | 1 | 172.31.2.196 | ONLINE | 0 | 0 | 512 | +-----------+--------------+---------+---------+-----------------+------------+ so to change its status Gracefully for maintenance set the status to OFFLINE_SOFT and if you think you need to make offline immediately set its status to OFFLINE_HARD(Immediately) we can do it with a simple command mysql> UPDATE mysql_servers SET status='OFFLINE_SOFT' WHERE hostname='172.31.2.162'; 5. Configure Query Rules we need to create query rules to route our traffic on the basis we want. 1. For SELECT To send all SELECT queries on the slave ( based on Regex ), we will set a regex to check for queries starting with select. Admin> INSERT INTO mysql_query_rules (active, match_digest, destination_hostgroup, apply) VALUES (1, '^SELECT.*', 1, 0); Query OK, 1 row affected (0.00 sec) Let's check the status of the regex mysql> SELECT rule_id, match_digest,destination_hostgroup hg_id, apply FROM mysql_query_rules WHERE active=1; +---------+---------------------+-------+-------+ | rule_id | match_digest | hg_id | apply | +---------+---------------------+-------+-------+ | 1 | ^SELECT.* | 1 | 0 | +---------+---------------------+-------+-------+ 2. For Update Again we will use the regex to route or traffic to the master MySQL host mysql> INSERT INTO mysql_query_rules (active, match_digest, destination_hostgroup, apply) VALUES (1, '^SELECT.*FOR UPDATE', 0, 1); Query OK, 1 row affected (0.00 sec) Let's check the status of the regex mysql> SELECT rule_id, match_digest,destination_hostgroup hg_id, apply FROM mysql_query_rules WHERE active=1; +---------+---------------------+-------+-------+ | rule_id | match_digest | hg_id | apply | +---------+---------------------+-------+-------+ | 1 | ^SELECT.* | 1 | 0 | | 2 | ^SELECT.*FOR UPDATE | 0 | 1 | +---------+---------------------+-------+-------+ 2 rows in set (0.00 sec) we see that we have 2 rows for select and update with host group id 1 for select and host group id 0 for select and after every update in setting run the below command. 2. For Updatemysql> LOAD MYSQL QUERY RULES TO RUNTIME; Query OK, 0 rows affected (0.00 sec) mysql> SAVE MYSQL QUERY RULES TO DISK; Query OK, 0 rows affected (0.08 sec) 6. Check Configuration: In our case, the user "sysbench" has a default_hostgroup=0, therefore any query not matching the above rules will be sent to host group 0 . Below stats, tables are used to validate if your query rules getting used by incoming traffic. we can check our configuration like below mysql> SELECT rule_id, hits, destination_hostgroup hg FROM mysql_query_rules NATURAL JOIN stats_mysql_query_rules; +---------+------+----+ | rule_id | hits | hg | +---------+------+----+ | 1 | 0 | 1 | | 2 | 0 | 0 | +---------+------+----+ also, we can validate our DB connection for the same user on the proxy server itself. root@ip-172-31-2-24:/home/kapendra.singh# mysql -u sysbench -psysbench -h 127.0.0.1 -P6033 -e "SELECT @@server_id" mysql: Using a password on the command line interface can be insecure. +-------------+ | @@server_id | +-------------+ | 2 | +-------------+ Conclusion: we tried to cover the most useful scenarios and queries that can be used for monitoring our backend MySQL database. However, we can always push this data to several monitoring services like Nagios, Icinga, datadog, and others with custom-made plugins available. Don't get scared to get your hands dirty in experimenting with ProxySQL as a monitoring solution for MySQL. Read the full article
0 notes
Text
Impact Of Data Migration On The Scalability And Flexibility Of Cloud Computing Architectures

Data migration has emerged as a critical procedure that influences scalability and flexibility as more and more companies migrate their infrastructure to the cloud. Data migration involves transferring data from one system to another while keeping it safe and readily available.
Additionally, choose B.tech from Bansal Group of Institutes, the top B.tech college in Bhopal 2023–2024, if you want to master data migration.
Data Migration: What Is It?
Data migration, which entails moving data from one location or system to another, is essential for system upgrades, database consolidations, and adjustments to the cloud computing architecture. To prevent delays and maintain the scalability and flexibility of the new system, proper planning and execution of the process are vital.
How Do The Four Types Of Data Migration Work?
Below is a list of the main categories of data migration:
1. Storage Migration
When analysing how data migration affects the scalability and flexibility of cloud computing platforms, storage migration is a crucial component. To ensure that the transfer process goes well without any downtime or abnormalities, meticulous preparation and testing are necessary.
Additionally, the success of your storage migration process depends on your ability to select a dependable storage solution that can handle your expanding data and shifting business requirements.
2. Migration Of Databases
Database migration must be handled carefully in order to complete a data migration project successfully. Database migration is the movement of data, either homogeneous or heterogeneous, between different types or versions of database management systems.
Making sure that all the source data is accurately transferred to the destination system without any errors or data loss is essential to the process. In addition to rigorous preparation and execution, post migration monitoring is crucial to guarantee that the new system performs as expected and that there are no performance concerns.
3. Migration Of Applications
Application migration refers to the process of moving a whole application from one environment to another. Its goal is to increase an application is flexibility and scalability when running on a more responsive platform within a cloud-based architecture.
Although this has several advantages for users, including better performance and flexibility, there are some difficulties that must be carefully handled. Compatibility problems with the new platform, slow data transfers, and significant downtime throughout the migration process are some of these difficulties.
What Methods Are There For Data Migration?
It is crucial to have a practical strategy in place before starting a data migration procedure. Understanding your present data storage needs and overcoming obstacles while moving to a new environment are necessary for a successful data transfer project. By choosing the best strategy, such as re-platforming or refactoring, this can be accomplished.
During a migration, it is also crucial to take needs for data governance compliance and security into account. Utilising the services and tools provided by cloud providers will help to streamline the procedure while requiring time consuming preparation for future scalability and flexibility requirements.
Additional search terms database best practice data quality centre merger server upgrading downtime premise on premises storage integration with time. Cloud based business operations extraction of a backup application stakeholders in the format computing system emergency recovery management of warehouses mapping previous Oracle environment, trickle source SQL huge bang Ibm source lake anomalies Consolidation of transformation analytics and acquisition and rearrangement marketplaces after migration MySQL activity metadata enhancement.
What Steps Comprise Data Migration?
Transferring data across systems or storage environments is known as data migration. To ensure a seamless and successful migration, it requires planning, getting ready, carrying it out, and validating the results. The general steps involved in data migration are as follows:
1. Specify Your Goals
Establish the data migration project's goals and objectives. Determine the motivations for the move, such as system upgrades, database consolidation, or a shift to a new platform.
2. Evaluate The Available Data
Examine the present data environment taking into account the different data kinds, volume quality and dependencies. Determine any potential problems or difficulties that might emerge during migration.
3. Prepare Your Migration Plan
Create a thorough strategy with deadlines, resources and a budget. Define the parameters for the data mapping, transformation, and migration requirements.
4. Data Backup And Security
Make data backups before migrating to safeguard the security and integrity of your data. This guarantees that, should there be any problems with the migration, you can return to the initial state.
5. Data Mapping And Transformation
Determine how the source and target systems are mapped. Identify the translations or transformations that will be made to data items, fields, and data structures during migration.
The Final Say
Cloud computing infrastructures' scalability and flexibility may be severely impacted by data transfer. This complex procedure, which involves moving data from one system or storage device to another, can cause corporate activities to be disrupted if improperly planned.
About BGI
The Bansal Group of Institutes offers a wide range of engineering, management, and nursing courses. It has the best and top-placement colleges in its various campuses across Bhopal, Indore, and Mandideep. With credible faculty and well-equipped laboratories, BGI ensures a top-notch learning experience.
Visit Our Websites
Bhopal- https://bgibhopal.com/
Indore- https://sdbc.ac.in/Mandideep- https://bce.ac.in/ Click on the link to get yourself registered- https://bgibhopal.com/registration-form/
0 notes
Text
System Center Configuration Manager current branch 1810 KB4486457 available

System Center Configuration Manager current branch 1810 KB4486457 available.
Issues that are fixed
First wave issues Synchronization of Office 365 updates may fail after you update to Configuration Manager current branch, version 1810. Errors messages that resemble one of the following are recorded in the WSyncMgr.log file: ProcessFileManifest() failed to process O365 file manifest. Caught exception: System.Net.WebException: An exception occurred during a WebClient request. ProcessFileManifest() failed to process O365 file manifest. Caught exception: System.UriFormatException: Invalid URI: The URI scheme is not valid. The distribution point upgrade process may fail. This causes a block of additional content distribution to that server. Errors messages that resemble the following are recorded in the distmgr.log file: Failed to copy D:\SRVAPPS\Microsoft Configuration Manager\bin\x64\ccmperf.dll to \\{server}\SMS_DP$\sms\bin\ccmperf.dll. GLE = 32 All superseded updates are removed and no are longer applicable on a client, even before expiration. This issue occurs even if the Do not expire a superseded software update until the software update is superseded for 3 months option is enabled. Performance improvements have been made to the Data Replication Service for device discovery data. The second and successive phases of a deployment start automatically after the success of the first phase, regardless of start conditions. Phased deployment deadline behavior settings are inconsistent between the Create Phased Deployment Wizard and the Phase Settings properties. When you run a Servicing Plan after you select a Product Category, the filter is not added correctly. The Cloud Management Gateway (CMG) content service is not created correctly when the CMG role is added after you update to Configuration Manager current branch, version 1810. The No deployment package option is selected after you change the properties of an Automatic Deployment Rule (ADR). After this update rollup is applied, affected ADRs can be re-created and their properties changes without any further issue. The Configuration Manager Message Processing Engine (MPE) may not always process Active Directory discovery data when optional attributes are added. Errors that resemble the following are recorded in the SMS_Message_Processing_Engine.log: ERROR: Got SQL exception when handle discovery message. Exception: System.Data.SqlClient.SqlException (0x80131904): String or binary data would be truncated.~~ The Service Connection Tool (serviceconnection.exe) fails and you receive the following error message when you use the -connect parameter: ERROR: System.IO.Exception : The directory is not empty. A user without Full Administrator rights may be unable to create or edit Windows Defender ATP Policies, even when you add them to the Endpoint Protection Manager security role. The Prerequisite Installation Checker incorrectly gives the option to retry a site installation again. If a second retry is tried, the administrator must run the Configuration Manager Update Reset Tool (CMUpdateReset.exe) to resolve the issue. Processing of .bld files by the SMS_Notification_Manager component takes longer than expected. This leads to delays in processing data and a backlog of files in the \inboxes\bgb.box folder. After you update to Configuration Manager current branch, version 1810, remote SQL providers who use Microsoft SQL Server 2014 or an earlier version may not always query the database. Errors that resemble the following are recorded in the smsprov.log: *** User $' does not have permission to run DBCC TRACEON. The Software Updates Patch Downloader component retries updates, up to three times. These retries fail and return error code 404. Windows Server 2016 updates are displayed incorrectly as available when you schedule updates to a Windows Server 2019 operating system image. Searching for a user’s first or last name, or full name, returns no results from the Overview section of the Assets and Compliance node of the Configuration Manager console. This issue occurs even when full discovery data is available. Globally available release issues After you enable support for express installation files, content may not always download from Windows Server Update Services (WSUS) servers in the following scenarios: Configuration Manager client installation through Software Update Point Installing updates directly from WSUS Windows Feature on Demand (FOD) or Language Pack (LP) acquisition After you update to Configuration Manager current branch, version 1810, device enrollment can overwrite Windows telemetry collection values that were previously set by Group Policy. This issue can cause value toggling between full and basic, for example, when Group Policy is applied. Hardware inventory is updated to include information about add-ins for Office365 and standalone Office products. Desktop Analytics deployment plans show a larger device count in the Configuration Manager console than in the Desktop Analytics Portal. Configuration Manager client setup may fail over a metered (for example, cellular) network connection. This may occur even if client policy settings allow for those connections. An error message that resembles the following is recorded in the Ccmsetup.log file on the client: Client deployment cannot be fulfilled because use of metered network is not allowed. Client setup may fail because of SQL Server CE schema changes. Errors that resemble the following are recorded in the Ccmsetup-client.log on the client: MSI: Setup was unable to compile Sql CE script file %windir%\CCM\DDMCache.sqlce. The error code is 80040E14. If an application is in a partly compliant state, and the client sees that a dependency is installed but the main application is not and requires re-enforcement, available deployment causes the following issues: The application is displayed as required or past due even though the deployment is available and there is no supersedence relation. Clicking Install has no effect. Sign in to Azure services fails when you use the Create Workflow in the Azure Services Wizard, even when correct credentials are used. Configuration Manager setup may fail the prerequisite check during installation or an update of a site server. This issue occurs if the environment uses SQL Always On. The “Firewall exception for SQL Server” rule shows a status of failed, and errors messages that resemble the following are recorded, even if the correct firewall exceptions are configured: ERROR: Failed to access Firewall Policy Profile. ERROR: Failed to connect to WMI namespace on Firewall exception for SQL Server; Error; The Windows Firewall is enabled and does not have exceptions configured for SQL Server or the TCP ports that are required for intersite data replication. The alternative download server that is listed in the "Specify intranet Microsoft update service location" window is not propagated to the Group Policy settings on the client. The download of Office 365 updates, such as “Semi-annual Channel Version 1808 for x86 Build 10730.20264” or “Monthly Channel Version 1812 for x64 Build 11126.20196” may fail. No errors are logged in the Patchdownloader.log file. However, entries that resemble the following are logged in the AdminUI.log log: (SMS_PackageToContent.ContentID={content_ID},PackageID='{package_ID}') does not exist or its IsContentValid returns false. We will (re)download this content. Read the full article
1 note
·
View note
Text
Sql server 2016 express run as

Sql server 2016 express run as how to#
Sql server 2016 express run as install#
Sql server 2016 express run as software#
This grid has a great comparison of what changed with columnstore over the years. You want to use columnstore indexes – I’m going to call this the minimum version I’d start with because they were finally updatable and could have both columnstore and rowstore indexes on the same table.You have compliance needs for a new application – And I’m specifically calling out new apps here, but 2016 adds Always Encrypted, Dynamic Data Masking, Row Level Security, and temporal tables, features which make it easier for you to build things to protect and track your valuable data.
Sql server 2016 express run as install#
You want to stay here until 2025-2026 – this version has more years left in its support life than SQL Server 2012/2014, so you can install it once and stick around longer.
You use Standard Edition – because it supports 128GB RAM (and can even go beyond that for some internal stuff like query plans.).
Sql server 2016 express run as how to#
You want an extremely well-known, well-documented product – it’s pretty easy to find material off the shelf and hire people who know how to use the tools in this version.
This meant you could write one version of your application that worked at both your small clients on Standard, and your big clients on Enterprise.
Sql server 2016 express run as software#
You’re an independent software vendor (ISV) – because 2016 Service Pack 1 gave you a lot of Enterprise features in Standard Edition.You still have to put in time to find the queries that are gonna get slower, and figure out how to mitigate those.Ģ014 also introduced a few other features that don’t sound like assets today: In-Memory OLTP, which wasn’t production-quality at the time, Buffer Pool Extensions, data files in Azure blobs, backing up to a URL, and Delayed Durability. You need faster performance without changing the code, and you have lots of time to put into testing – 2014’s Cardinality Estimator (CE) changes made for different execution plans, but they’re not across-the-board better.You use log shipping as a reporting tool, and you have tricky permissions requirements (because they added new server-level roles that make this easier.).You need to encrypt your backups, and you’re not willing to buy a third party backup tool.I’d just consider this a minimum starting point for even considering AGs (forget 2012) because starting with 2014, the secondary is readable even when the primary is down. You want to use Always On Availability Groups – but I’m even hesitant to put that here, because they continue to get dramatically better in subsequent versions.You’re dealing with an application whose newest supported version is only SQL Server 2014, but not 2016 or newer.In all, I just can’t recommend 2012 new installs today. You either don’t need robust encryption for your backups, or you’re willing to buy a third party tool to get it.Ģ012 introduced a few other features – Availability Groups, columnstore indexes, contained databases, Data Quality Services – but they were so limited that it’s hard to consider this a good starting point for those features today.You’re comfortable being out of support (because support ends in July 2022.).You’re dealing with an application whose newest supported version is only SQL Server 2012, but not 2014 or newer.But I got a really good deal on this CD at a garage sale You should consider SQL Server 2012 if… I’m going to go from the dark ages forward, making a sales pitch for each newer version. I know, management wants you to stay on an older build, and the vendor says they’ll only support older versions, but now’s your chance to make your case for a newer version – and I’m gonna help you do it. Are you sure you’re using the right version? Wait! Before you install that next SQL Server, hold up.
0 notes
Text
How Sticking with Dynamics NAV Can Bring Your Business Down?
Upgrade NAV to BC / By Trident Information Systems
The major reason for your business to suffer if you choose to stick to Dynamics NAV is its end of support which will eventually leave you on your own. Dynamics NAV 2017 version met its end-of-life-cycle support in Jan 2022, whereas Dynamics NAV 2018’s support is still viable till Jan 2023 leaving you a noticeably short time to optimize it further. It is best to Upgrade NAV to Business Central.
Some businesses still use Dynamics NAV to support their production environment. The decision to stick to the older version could be derived from its perceived stability: it can resolve all the issues and does exactly what it is expected to do.
Alternatively, a business may decide to delay its NAV to BC Upgrade to save IT capital cost while “sweating” its resources to extract maximum return on investment. However, this approach will eventually lead to the business’s downfall as it can collapse anytime.
What Would Happen If You Still Glued with Dynamics Nav Without Support?
You are welcoming a huge security risk, limited disaster recovery options, no more updates and patches, and a lack of functionality if you still expect Dynamics NAV to facilitate core functionalities to your business. Hence Upgrade NAV to Business Central.
A Massive Security Threat
Once your vendor ends the support for Dynamics NAV, you are no longer entitled to the relevant upgrades or patches. You will no longer receive any support for issues occurring in the application. Since you cannot resolve them on your own, the application starts posing a risk to your overall business rather than a medium for its growth.
Limited Disaster Recovery
Not having NAV to Business Central Upgrade means no more support from Microsoft leaves businesses to struggle on their own. Suppose if something wrong happens to the application and the entire environment demands a rebuild, the user is liable to source the correct version (which is not so easy). In this scenario, businesses will have to track aged operating system and SQL Server versions. This can even jeopardize your security and lead to data loss or data theft by hackers.
In the worst-case scenario, you may not even get to access the older version and require an urgent NAV to Dynamics 365 Business Central upgrade. An upgrade project can take a good sum of time. Even if the upgrade is planned, it can take up to months to complete. Leaving you with months of downtime and eventually, making your production suffer.
Functionality Deficiency
Many businesses who have been paying for maintenance licensing are entitled to access the latest NAV versions. However, delaying the upgrade is not useful either. Upgrade NAV to Business Central as Microsoft Dynamics 365 has a pedigree of ongoing developments and upgrades. For more than three decades, NAV has been redefined to provide greater functionalities. No doubt, it provided great services to its users, but the end of support will reverse the situation. The user can no longer access the new upgrades and functionalities while declining productivity.
So, what is the Solution?
The only solution is to Upgrade NAV to Business Central. Microsoft introduced Business Central on April 2nd, 2018. The newer technology delivers more robust features, tailored functionalities, and a more agile interface. It did not take too long to conquer a special place among SMBs as one of the most reliable, flexible, and scalable ERPs (Enterprise Resource Planning). The NAV to Business Central Upgrade Enables – advanced mobile access, application integration, custom adaptability, seamless upgrades, affordability, and reporting capabilities.
However, besides worrying about training employees for a newer version, heavy historical data transition brings chills down the user’s spine. Little do they realize that the data structure of NAV and BC is the same. Thus, if your data is organized and corruption-free, you are good to go.
Dynamics 365 Business Central automatically upgrades your application frequently without disturbing your business’s ecosystem, and twice a year with major upgrades, for which the user is notified a couple of days prior.
Dynamics 365 BC is a cloud-based application that enables remote control, which means it is accessible anytime, anywhere, from any device. Thus, leaving you no scope for investing in hardware, server, and maintenance agreements.
The data is completely secured as 3,500 cyber-security experts are protecting, responding, and detecting cyber threats.
Business Central endorses faster and more flexible financial reporting via Jet Reports and Power BI (Business Intelligence). Machine learning and AI (Artificial Intelligence) (Artificial Intelligence) support tools monitor and forecast more precise data.
Its flexible licensing fees enable the user to manage cash flow. Instead of an annual enhancement, you only pay per user every month.
Bottom Line
No matter how efficient you perceive your Dynamics NAV to be, the fact remains that it is on the verge of its life. It is recommended to Upgrade NAV to Business Central as soon as possible as it will define your business’s future. If you are planning for a NAV to BC Upgrade, contact Trident Information Systems. We are Dynamics 365 Business Central Gold Partner and LS Central Diamond Partner.
http://tridentinfo.ae/how-sticking-with-dynamics-nav-can-bring-your-business-down-%ef%bf%bc/
#dynamics 365 business central partner in Saudi Arabia#dynamics 365 business central partner in Dubai#dynamics 365 business central partner in UAE#dynamics 365 business central partner in Nigeria#dynamics 365 business central partner in Kenya#dynamics 365 business central partner in Ethiopia#dynamics 365 business central partner in Qatar#dynamics 365 business central partner in Kuwait#dynamics 365 business central partner in Oman
0 notes
Text
How Kucoin clone script is best for starting crypto business?
After going through various articles and information regarding the initiation of the crypto exchange business like Kucoin, the Kucoin clone script might be the term that has crossed often. Being an entrepreneur, one would’nt engage with any specific method just because they recognized it. A detailed analysis is required to ensure its efficiency.
Likely, the Kucoin clone script might be the term that could have come across every entrepreneur’s business journey. Speaking of which, it is the best result-oriented development methodology. But, there exist much confusion, whether this Kucoin clone script will be the best choice or not. Without a delay let’s dive into this topic deeper,
As you might know, a Kucoin clone script is a pre-fabricated crypto exchange software that comprises all essential features for a crypto exchange like Kucoin to run seamlessly.
Features of Kucoin clone script
High-Performance Matching Engine
Spot Trading
Margin Trading
Futures Trading
P2P Trading
OTC Trading
User Dashboard
Admin Dashboard
Extended Trade View
KYC/AML
Referral program
Crypto/Fiat Payment Gateway integration
Buy/Sell advertisements
User to user exchange BUY/SELL
Security Features
Jail Login
Two-Factor Authentication
Cloudflare Integration
SQL Injection Prevention
End-To-End Encryption Based SSL
Anti Denial Of Service(Dos)
Cross-Site Request Forgery Protection
Server-Side Request Forgery Protection
Anti Distributed Denial Of Service
Apart from these features, there are various other benefits that made this Kucoin clone software the best fit for starting a crypto exchange business.
Easy Customization
With the help of the Kucoin clone script, you will be able to make the necessary customizations to your crypto exchange. Apart from the in-built features, more security features can be added to enhance the exchange’s competency.
Instant Deployment
Making use of this Kucoin clone script, your overall time period for launching a crypto exchange reduces to the ground level. Being a prefabricated one, after making required changes and customizations your crypto exchange will be ready for launch with complete perfection.
Cost-effective
Apart from other benefits, the Kucoin clone script supports the majority of the budding entrepreneurs with its affordable budget. Instead of spending a pile of money with the other development methodologies, making use of this Kucoin clone script helps to save a huge portion of your budget.
High success Ratio
As this Kucoin clone script is developed with a skillful team of experts, the script itself exists with a professional touch. With such a masterpiece you could possibly stand out from the crowd when compared to other amateur competitors. Grabbing a wide volume of traders to your exchange stands as the main factor for your success.
To get these benefits offered by a Kucoin clone script, all you have to do is to pick the best crypto exchange clone script provider among the various ones.
0 notes
Text
Comparing RonDB 21.04.0 on AWS, Azure and GCP using Sysbench
Release of RonDB 21.04.0RonDB is based on MySQL NDB Cluster optimised for use in modern cloud settings. Today we launch RonDB 21.04.0. In RonDB 21.04.0 we have integrated benchmark scripts to execute various benchmarks towards RonDB.There are three ways of using RonDB. The first is using the managed version provided by Logical Clocks. This is currently available in AWS and is currently being developed to also support Azure. This is still in limited access mode. To access it contact Logical Clocks at the rondb.com website.The second way is to use a script provided by Logical Clocks that automates the creation of VMs and the installation of the software components required by RonDB. These scripts are available to create RonDB clusters on Azure and GCP (Google Cloud). This script can be downloaded from nexus.hops.works/rondb-cloud-installer.sh.The third manner to use RonDB is to simply download the RonDB binary tarball and install it on any computers of your own liking.All these methods start by visiting http://rondb.com. From here you will find the download scripts, the tarball to download and to send an email request access to the managed version of RonDB.RonDB 21.04.0 can be used in any of the above settings, but we focus our development, testing and optimisations towards executing RonDB in an efficient manner in AWS, Azure and GCP. We will likely add Oracle Cloud eventually to the mix as well.Benchmark SetupWhat we have discovered in our benchmarking is that even with very similar HW there are some differences in how RonDB performs on the different clouds. So this report presents the results using very similar setups in AWS, Azure and GCP.Above we have the benchmark setup used in all the experiments. There are always 2 RonDB data nodes and they are replicas of each other. Thus all write operations are written on both data nodes to ensure that we are always available even in the presence of node failures.The MySQL Servers are pure clients since data is located on the RonDB data nodes. Thus we can easily scale the benchmark using any number of MySQL Servers. The benchmark application runs on a single VM that sends SQL queries to the MySQL Servers and receives results using a MySQL client written in C. It is sufficient to have a single Sysbench server for these experiments.In this experiment we will scale RonDB data nodes by using different VM types. It is also possible to scale RonDB by adding more RonDB data nodes. Both of these changes can be performed without any downtime.It is possible to execute the Sysbench server local to the MySQL Server and let multiple Sysbench servers execute in parallel. This would however be a 2-tiered cluster and we wanted to test a 3-tiered cluster setup since we think this is the most common setup used. Obviously a 2-tiered cluster setup will have lower latency, but it will also be more complex to maintain.There is also a RonDB management server in the setup, however this is not involved in the benchmark execution and is either located in the Sysbench server or a separate dual CPU VM. Availability ZonesAWS, Azure and GCP all use a concept called Availability Zones. These are located in the same city, but can be distant from each other. The latency between Availability Zones can be more than 1 millisecond in latency for each jump. RonDB contains options to optimise for such a setup, but in this test we wanted to test a setup that is within an Availability Zone.Thus all setups we ensured that all VMs participating in cluster setup were in the same zone. Even within a zone the variance on the latency can be substantial. We see this in that the benchmark numbers can vary even within the same cloud and the same availability zone on different runs. From other reports it is reported that network latency is around 40-60 microseconds between VMs in the same availability zone. Our experience is that it is normal that this latency varies at least 10-20 microseconds up or down. In Azure it is even possible that the variance is higher since they can implement some availability zones in multiple buildings. In this case Azure provides a concept called Proximity Placement Groups that can be used to ensure that VMs are located in the same building and not spread between buildings in the same availability zone.RonDB VM TypesAll cloud vendors have VMs that come from different generations of SW and HW. For a latency sensitive application like RonDB this had serious implications. All the VMs we tested used very similar Intel x86 CPUs. There is some difference in performance between older Intel x86 and newer CPUs. However this difference is usually on the order of 30-40%, so not so drastic.However an area where innovation has happened at a much higher pace is networking. Cloud vendors have drastically improved the networking latency, bandwidth and efficiency from generation to generation.What we found is that it is essential to use the latest VM generation for MySQL Servers and RonDB data nodes. The difference between the latest generation and the previous generation was up to 3x in latency and performance. We found that the latest generation of VMs from all cloud vendors have similar performance, but using older versions had a high impact on the benchmark results. All the benchmarking results in this report uses the latest generation of VMs from all vendors.For AWS this means using their 5th generation VMs. AWS has three main categories of VMs, these c5, m5 and r5. c5 VMs are focused on lots of CPU and modest amounts of memory. m5 VMs twice as much memory with the same amount of CPU and r5 have 4x more memory than the c5 and the same amount of CPU. For RonDB this works perfectly fine. The RonDB data nodes store all the data and thus require as much memory as possible. Thus we use the r5 category here. MySQL Servers only act as clients in RonDB setup, thus require only a modest amount of memory, thus we use the c5 category here.The latest generation in Azure is the v4 generation. Azure VMs have two categories, the D and E VMs. The E category has twice as much memory as the D category. The E category is similar to AWS r5 and the D category is similar to the AWS m5 category.The latest generation in GCP is the n2 generation. They have n2-highcpu that matches AWS c5, n2-standard that matches AWS m5 and n2-highmem that matches AWS r5. GCP also has the ability to extend memory beyond 8 GB per CPU which is obviously interesting for RonDB.Benchmark Notes on Cloud VendorsSince we developed the RonDB managed version on AWS we have a bit more experience from benchmarking here. We quickly discovered that the standard Sysbench OLTP RW benchmark actually is not only a CPU benchmark. It is very much a networking benchmark as well. In some benchmarks using 32 VCPUs on the data nodes, we had to send around 20 Gb/sec from the data node VMs. Not all VM types could handle this. In AWS this meant that we had to use a category called r5n. This category uses servers that have 100G Ethernet instead of 25G Ethernet and thus a 32 VCPU VM was provided with bandwidth up to 25G. We didn’t investigate this thoroughly on Azure and GCP.Some quirks we noted was that the supply of Azure v4 VM instances was somewhat limited. In some regions it was difficult to succeed in allocating a set of large v4 VM instances. In GCP we had issues with our quotas and got a denial to increase the quota size for n2 VMs, which was a bit surprising. This meant that we executed not as many configurations on Azure and GCP. Thus some comparisons are between Azure and AWS only.Using the latest VM generation AWS, Azure and GCP all had reasonable performance. There were differences of course, but between 10-30% except in one benchmark. Our conclusion is that AWS, Azure and GCP have used different strategies in how to handle networking interrupts. AWS reports the lowest latency on networking in our tests and this is also seen in other benchmark reports. However GCP shows both in our benchmarks and other similar reports to have higher throughput but worse latency. Azure falls in between those.Our conclusion is that it is likely caused by how network interrupts are handled. If the network interrupts are acted upon immediately one gets the best possible latency. But at high loads the performance goes down since interrupt handling costs lots of CPU. If network interrupts are instead handled using polling the latency is worse, but at high loads the cost of interrupts stays low even at extreme loads.Thus best latency is achieved through handling interrupts directly and using polling one gets better performance the longer the delay in the network interrupt. Obviously the true answer is a lot more complex than this, but suffice it to say that the cloud vendors have selected different optimisation strategies that work well in different situations.Benchmark Notes on RonDBOne more thing that affects latency of RonDB to a great extent is the wakeup latency of threads. Based on benchmarks I did while at Oracle I concluded that wakeup latency is about 2x higher on VMs compared to on bare metal. On VMs it can be as high as 25 microseconds, but is likely nowadays to be more like on the order of 10-15 microseconds.RonDB implements adaptive CPU spinning. This ensures that latency is decreasing when the load increases. This means that we get a latency curve that starts a bit higher, then goes down until the queueing for CPU resources starts to impact latency and after that it follows a normal latency where latency increases as load increases.Latency variations are very small up to about 50% of the maximum load on RonDB.In our benchmarks we have measured the latency that 95% of the transactions were below. Thus we didn’t focus so much on single outliers. RonDB is implementing soft real-time, thus it isn’t intended for hard real-time applications where life depends on individual transactions completing in time.The benchmarks do however report a maximum latency. Most of the time these maximum latencies were as expected. But one outlier we saw, this was on GCP where we saw transaction latency at a bit above 200 ms when executing benchmarks with up to 8 threads. These outliers disappeared when going towards higher thread counts. Thus it seems that GCP VMs have some sort of deep sleep that keeps them down for 200 ms. This latency was always in the range 200-210 milliseconds. Thus it seemed that there was a sleep of 200ms somewhere in the VM. In some experiments on Azure we saw even higher maximum latency with similar behaviour as on GCP. So it is likely that most cloud vendors (probably all) can go into deep sleeps that highly affect latency when operations start up again.Benchmark ConfigurationOk, now on to numbers. We will show results from 4 different setups. All setups use 2 data nodes. The first setup uses 2 MySQL Servers and both RonDB data nodes and MySQL Servers use VMs with 16 VCPUs. This setup mainly tests latency and performance of MySQL Servers in an environment where data nodes are not overloaded. This test compares AWS, Azure and GCP.The second setup increases the number of MySQL Servers to 4 in the same setup. This makes the data node the bottleneck in the benchmark. This benchmark also compares AWS, Azure and GCP.The third setup uses 16 VPUs on data nodes and 2 MySQL Servers using 32 VCPUs. This test shows performance in a balanced setup where both data nodes and MySQL Servers are close to their limit. This test compares AWS and Azure.The final setup compares a setup with 32 VCPUs on data nodes and 3 MySQL Servers using 32 VCPUs. This setup mainly focuses on behaviour latency and throughput of MySQL Servers in an environment where the data nodes are not the bottleneck. The test compares AWS with Azure.We used 3 different benchmarks. Standard Sysbench OLTP RW, this benchmark is both a test of CPU performance as well as networking performance. Next benchmark is the same as OLTP RW using a filter where the scans only return 1 of the 100 scanned rows instead of all of them. This makes the benchmark more CPU focused.The final benchmark is a key lookup benchmark that only sends SQL queries using IN statements. This means that each SQL query performs 100 key lookups. This benchmark shows the performance of simple key lookups using RonDB through SQL queries.ConclusionsThe results show clearly that AWS has the best latency numbers at low to modest loads. At high loads GCP gives the best results. Azure has similar latency to GCP, but doesn’t provide the same benefits at higher loads. These results are in line with similar benchmark reports comparing AWS, Azure and GCP.The variations from one benchmark run to another run can be significant when it comes to latency. This is natural since there is a random latency added dependent on how far apart the VMs are within the availability zone. However throughput is usually not affected in the same manner.In some regions Azure uses several buildings to implement one availability zone, this will affect latency and throughput negatively. In those regions it is important to use Proximity Placement Groups in Azure to ensure that all VMs are located in the same building. The effect of this is seen in the last benchmark results in this report.The limitations on VM networking are a bit different. This played out as a major factor in the key lookup benchmark where one could see that AWS performance was limited due to network bandwidth limitation. Azure VMs had access to a higher networking bandwidth for similar VM types.AWS provided the r5n VM types, this provided 4x more networking bandwidth with the same CPU and memory setup. This provided very useful for benchmarking using RonDB data nodes with 32 VCPUs.Benchmark Results2 Data Nodes@16 VCPUs, 2 MySQL Server@16 VCPUsStandard OLTP RWIn this benchmark we see clearly the distinguishing features of AWS vs GCP. AWShas better latency at low load. 6,5 milliseconds compared to 9,66 milliseconds.However GCP reaches higher performance. At 128 threads it reaches 7% higherperformance at 7% lower latency. So GCP focuses on the performance at high loadwhereas AWS focuses more on performance at lower loads. Both approaches haveobvious benefits, which is best is obviously subjective and depends on the application.This benchmark is mainly testing the throughput of MySQL Servers. The RonDBdata nodes are only loaded to about 60-70% of their potential throughput with2 MySQL Servers.Moving to latency numbers one can see the same story, but even clearer. AWS hasa better latency up to 48 threads where the latency of GCP becomes better. In GCPwe see that the latency at 1 thread is higher than the latency at 12 threads and onlyat 24 threads the latency starts to increase beyond the latency at 1 thread. Thus inGCP the latency is very stable over different loads until the load goes beyond 50%of the possible throughput. We see the same behaviour on Azure whereas AWSlatency slowly starts to increase at lower thread counts.Standard OLTP RW using filterThe OLTP RW using a filter is more focused on CPU performance. The major differenceis seen at higher loads. The latency at low loads is very similar, but at higher loads weget higher throughput at lower latency. Thus standard OLTP RW has a steeper marchfrom acceptable latency to high latency. The difference in throughput is very smallbetween cloud vendors, it is within 10%.The comparison between AWS and GCP is similar though. The GCP benefit at higherload is slightly higher and similar to the latency. The AWS advantage at lower loads isslightly lower. Thus GCP has a slight advantage compared to standard OLTP RW,but it is a very small difference.Key LookupsIn the graph below we see the number of key lookups that 2 MySQL Servers can drive.The numbers are very equal for the different cloud vendors. AWS as usual has anadvantage at lower thread counts and GCP gains the higher numbers at higherthread counts and Azure is usually in the middle.The latency numbers are shown below. These numbers more clearly show theadvantage of AWS at lower thread counts. At higher thread counts the latencyis mostly the same for all cloud vendors. This benchmark is extremely regularin its use case and thus it is mostly the CPU performance that matters in thisbenchmark. Since this is more or the less same on all cloud vendors we seeno major difference.2 Data Nodes@16 VCPUs, 4 MySQL Server@16 VCPUsIn this benchmark the bottleneck moves to the RonDB data nodes. We now havesufficient amounts of MySQL Servers to make the RonDB data nodes a bottleneck.This means a bottleneck that can be both a CPU bottleneck as well as a networkingbottleneck.Standard OLTP RWThe latency is very stable until we reach 64 threads where we have around 15k TPS at20 milliseconds latency. At higher thread counts the data nodes becomes the bottleneckand in this case the latency has a much higher variation. We can even see that latencyat 128 threads in Azure goes down and throughput up. We expect that this is due tointerrupt handling being executed on the same CPUs as database processing happens.This is something that we will look more into.OLTP RW using filterThe throughput of OLTP with a filter means that the focus is more on CPU performance.This makes it clear that the high variation on throughput and latency in standard OLTP RWcomes from handling the gigabytes per second of data to send to the MySQL Servers.In this benchmark the throughput increases in a stable manner and similarly the latencygoes up in an expected manner.All cloud vendors are very close to each other except at low thread counts whereAWS have an advantage.Key LookupsThe key lookups with 4 MySQL Server and 2 data nodes and all nodes using16 VCPUs per node moves the bottleneck to the data node. As usual AWSwins out on the latency at lower thread counts. But at higher thread countsAWS hits a firm wall. Most likely it hits a firm bandwidth limitation on the VMs.This limitation is higher on Azure, thus these VM can go an extra mile and serve1 million more key lookups per second.2 Data Nodes@16 VCPUs, 2 MySQL Server@32 VCPUsThis benchmark uses the same amount of CPUs on the MySQL Server side,but instead of divided on 4 MySQL Servers, it is using 2 MySQL Servers.We didn’t test GCP in this configuration. We expect no surprises in throughputand latency if we do.Standard OLTP RWIn the Standard OLTP RW we see that the throughput is the same as with4 MySQL Servers. However the throughput increases in a more regular manner.What we mainly see is that we can achieve a higher throughput using a smalleramount of threads in total. This makes the throughput more stable. Thus weconclude that at least up to 32 VCPUs it pays off to use larger MySQL Serversif required.2 Data Nodes@32 VCPUs, 3 MySQL Server@32 VCPUsIn this benchmark we increased the number of CPUs on the RonDB datanodes to 32 VCPUs. Most of the testing in this setup has been performedon AWS. The main reason for including the Azure numbers is becausethese numbers show the impact of not using Proximity Placement Groupsin Azure on large regions. We saw clearly in these benchmarks that thelatency in the Azure setup was much higher than in previous benchmarksthat were using a smaller region.However in the smaller region it was difficult to allocate these larger VMsin any larger number. We constantly got failures due to lacking resourcesto fulfil our requests.Standard OLTP RWIn AWS we discovered that the network was a bottleneck when executingthis benchmark. Thus we used r5n.8xlarge instead of r5.8xlarge VMs inthis benchmark. These VMs reside in machines with 100G Ethernetconnections and each 32 VCPU VM have access to at least 25 Gb/secnetworking. The setup tested here with 3 MySQL Servers doesn’t load theRonDB data node fully. In other benchmarks we were able to increasethroughput to around 35k TPS. However these benchmarks used a differentsetup, so these numbers are not relevant for a comparison. What we see isthat the throughput in this case is roughly twice the throughput when using16 VCPUs in the data nodes.Latency numbers look very good and it is clear that we haven't reallyreached the bottleneck really in neither the MySQL Servers nor theRonDB data nodes.OLTP RW using filterSimilarly in this experiment we haven’t really reached the bottleneck on neither theRonDB data nodes nor the MySQL Servers. So no real news from this benchmark. http://mikaelronstrom.blogspot.com/2021/04/comparing-rondb-21040-on-aws-azure-and.html
0 notes
Text
JAVA FULL STACK DEVELOPMENT
It is almost impossible to create a full-fledged software product using only one technology. This usually involves complete tech stacks – Standard combinations of tools and programming languages. As all software products consist of the client side and a server, there are usually two separate stacks that cover each of the layers. However, there are approaches that can be used to build web or mobile application from A to Z. These are called full stack development.
Accordingly, a generalist that has broad skills across all aspects of product engineering is usually called a full stack developer.
Being considered unicorns due to their rare expertise and versatility, they are in high demand for large companies and startups alike, from Facebook and eBay to Munchery, Betterment or Tinder.
As an idea of a person equally proficient at HTML/CSS, Python, and SQL has become more of a myth, the approach towards acquiring new skills and learning quickly has led to the appearance of specialists strong in one particular stack. Let’s see what the most popular stacks are and how they’re used.
When talking about full stack JavaScript the first thing that comes to mind is the MEAN stack. It is a technology bundle that includes MongoDB, Express, AngularJS, and Node.js.
However, with the rapid growth of this approach, more alternative options for full stack JavaScript development are added. While server-side JavaScript programming with Node.js and Express web framework is the most common technology choice, other Node.js-based tools, such as Meteor, Sails.js, Koa, restify or Keystone.js, might be used as well.
The choice of possible frameworks for the front-end JavaScript is even greater. Aside from traditional AngularJS or AngularJS 2.0 frameworks, numerous libraries, such as React, Vue.js, Knockout.js, or Backbone.js, are typically used, depending on the project specifics.
As for the database, almost any MongoDB alternative can be used: MySQL, PostgreSQL, Apache CouchDB or Apache Cassandra.
The Pros of Full Stack JavaScript Development
The fact that companies like Groupon, Airbnb, Netflix, Medium and PayPal adopted the full stack JavaScript approach to build some of their products speaks for itself. However, small start-ups seem to enjoy using it as well. This is mostly due to the number of benefits full stack programming offers.
Common language, better team efficiency with less resources
Having all parts of your web application written in JavaScript allows for better understanding of the source code within the team. Therefore, there is no such thing as a gap between front and back end engineering that occurs when two teams are working separately using different technologies. Moreover, you can now work with only one team instead of two, for back and front end, which should significantly reduce the cost and effort of finding and retaining the right talent. Such a cross-functional team is a great asset when following Agile methodologies.
(*) Extensive code reuse
With full stack JavaScript, you save time through code reuse and sharing. Following the “don’t repeat yourself” (DRY) principle, you might be able to reduce the effort by reusing the parts of the code (or sharing libraries, templates, and models) on both back and front end that are very close in terms of logic and implementation. In other words, you don’t need to think about the Java-script utility equivalents in Python or Ruby, you just use the same utility on the server and in the browser. Reducing the number of lines of code by up to 40 percent is also a valuable capability when refactoring and maintaining the source code.
(*) High performance and speed
Node.js uses event-driven, non-blocking IO model that makes it lightweight and fast as compared to other commonly used back end technologies. To prove this, PayPal published a comprehensive report on the results they have seen in the process of migrating from Java to full stack JavaScript. The company was able to make the development almost 2 times faster while reducing the engineering personnel involved. Moreover, they have seen a dramatic improvement in performance, doubling the number of requests completed per second and decreasing the average response time by 35 percent for the same page. This means that the pages are served 200ms faster, which is definitely a noteworthy result.
(*) Extensive knowledge base
Backed by giants like Facebook and Google, JavaScript has a powerful and fast-growing community. Based on the Stack Overflow survey from 2016 quoted above, the language tops the list of the most popular technologies on the website with 62,588 votes. The website currently lists 1,543,025 questions tagged “JavaScript”, which indicates the high activity of the developer community and the huge amount of valuable information that can be found there.
(*) Free & open source toolset
Most of the full stack JavaScript development tools are free or open source projects. This means you don’t need to bear additional expenses for costly licenses or subscriptions. The tools that are open sourced are updated regularly and evolving fast due to the active community contributions. Instead of relying on a fixed set of technologies, you may use any of more than 475,000 tools (which have doubled since last year), hosted by the npm, the largest JavaScript modules registry in the world.
The Cons of Full Stack JavaScript Approach
Yet, no technology is perfect. Despite all the benefits the full stack approach offers, there is always some drawbacks to be aware of.
(*) Insufficiency with computation-heavy back end
When it comes to heavy computation and data processing on the server side, Node.js is not the best option. There are lots of far better technologies to handle projects like machine learning, algorithms, or heavy mathematical calculations. Having a single CPU core and only one thread, that processes one request at a time, it might be easily blocked by a single computationally intensive task. While the thread is busy processing the numbers, your application won’t be able to work with other requests, which might result in serious delays. Yet, there are numerous ways to overcome this limitation. By simply creating child processes or breaking complex tasks into smaller independent microservices, that use more suitable technologies and communicate with your back end, you can handle complex computational tasks in Node.js.
Relatively young technologies
When compared with PHP or Java, server-side JavaScript has been around for a shorter period of time. This results in a smaller knowledge base and limited integration capabilities. As an example, some developers cite the immaturity of the connections between Node.js and relational database tools, such as MySQL, Microsoft SQL Server, and PostgreSQL.
(*) Jack of all trades, master of none?
It is a common belief that a developer can truly master only one area of knowledge. With every other skill gained the quality of his/her expertise will decline. While syntax and grammar of JavaScript are mostly the same on client and server side, there are still many details to consider. Aside from being proficient in front end development, full stack JavaScript developers need to have an expertise in back end programming, such as HTTP protocol, asynchronous I/O, data storage fundamentals, cookies, etc. That is why some say that there are really no full stack engineers: Every one of them is either front or back end oriented. However, we have all the reasons to disagree, based on our own experience and strong JavaScript skills.
Drawbacks of every separate tool in the stack combined
As every technology stack, MEAN combines the weak sides of all 4 its elements. Most of them are minor technical limitations, which appear under certain circumstance. However, in order to use the stack, it’s important to realize possible bottlenecks of every tool and adjust your development strategy accordingly.
0 notes